자바의 스트림 API가 빅데이터를 다루기 좋은 이유는 속도가 아니라 메모리 측면에서 다뤄진다.
스트림은 요소들을 메모리에 저장하지 않는다. (반면 컬렉션은 모든 요소를 메모리에 저장한다.)
스트림은 Source(컬렉션, 배열, 입출력 채널 등)로부터 입력받은 데이터를 처리하여 Destination으로 전달하는 파이프라인의 일종이다.
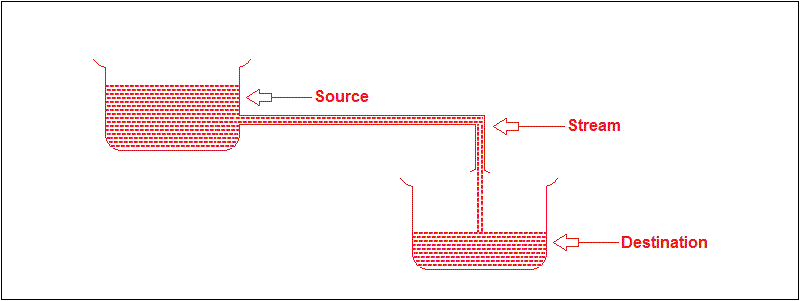
출처 - https://medium.com/elevate-java/java-streams-an-in-memory-data-structure-d6984eea1091
이 때, Source로부터 전체 데이터를 한번에 읽어들이지 않고 chunk by chunk로 가져온다. 즉, 엄청난 크기의 전체 데이터를 저장하기 위한 버퍼가 필요하지 않다는 의미이다.
현재 나의 수준에서 스트림을 이용한 경우는 Source가 컬렉션인 경우 밖에 없다. 그래서 '메모리에 저장하지 않는다'는 내용이 잠시 이해되지 않았다. Source가 빅데이터를 다루는 Kafka라고 생각해보자. (Destination은 인메모리가 아닌 외부 어딘가) 스트림은 Source로부터 입력받는 데이터를 처리하는 과정에서 전체 데이터를 수용하기 위한 공간은 할당하지 않기 때문에 자바 애플리케이션에서 메모리 걱정없이 빅데이터를 다룰 수 있는 도구가 된다.

